XML Group 端口
Version 26.2.9636
Version 26.2.9636
XML Group 端口
XML 组端口处理相关 XML 记录的集合,并按列对其进行分组,以实现高效的数据管理和分析。
核心功能
- 层级 XML 记录分组与聚合:支持基于键的分组以及多分组键操作。
- 聚合函数支持:支持通过 XPath 识别并执行 MIN(最小值)、MAX(最大值)、SUM(求和)、AVG(平均值)、COUNT(计数)和 CONCATENATE(串联)等函数。
- 保留原始结构:在添加汇总和分组元素的同时,保留原始记录的结构。
概述
XML 组端口通过聚合、验证和转换结构化数据来处理相关 XML 记录的集合,以便与各种系统无缝集成。它能够高效处理分层 XML 数据,确保数据交换、报告和自动化工作流等应用程序之间的一致性和互操作性。
端口配置
此部分包含所有可配置的端口属性。
组配置选项卡
与配置组相关的设置。
示例文件
使用 示例文件 切换按钮指定示例文件,允许端口提供有关文档的更多上下文。有关更多信息,请参阅 使用示例文件。
- 示例文件 选择一个现有的示例文件,或上传一个新的文件。
循环设置
与端口应使用的 XPath 相关的设置,用于表示输入文档中的单个记录,以及用于保存每组相关记录的 XML 元素。
- 元素名称 输出文件中用于分组的 XML 元素的名称。
- 记录 XPath 输入中的哪个 XPath 应该代表单个记录。
分组设置
定义每个记录中哪些元素用于确定每个组的键值的设置。有关更多信息,请参阅使用分组设置。
- 元素名称 告诉端口在输出文件中分组时要使用的 XML 元素的名称。这通常与 键值 XPath 指向的输入文件中的元素名称相同,但可以使用不同的名称。
- 键值 XPath 用作 key(要分组的依据)的元素的输入文件中的 XPath。键值 XPath 与 记录 XPath 相关。
- 添加键值 XPath 点击此按钮以定义其他键。
聚合设置
_使用聚合设置切换按钮查看定义如何汇总每个组中的记录的设置。有关更多信息,请参阅使用聚合设置。
- 元素名称 用于汇总记录的 XPath 的名称。
- 函数 用作聚合的函数。从 MIN、MAX、SUM、AVG、COUNT 和 CONCATENATE 中选择。
- XPath 要聚合的元素的相对 XPath。
- 添加聚合 XPath 点击此按钮以添加更多聚合 XPath。
排序依据设置
使用 排序依据 开关查看定义如何对每个组中的记录进行排序的设置。
- XPath 元素的相对 XPath,用于排序。
- 排序依据 按升序还是降序排序。
- 添加 XPath 排序依据 单击此按钮可添加更多 XPath 作为排序依据。
设置
配置
确定如何访问端口的设置。
- 端口 Id 端口的静态、唯一标识符。
- 端口类型 显示端口类型及其用途的描述。
- 端口描述 一个可选字段,用于提供端口及其在流中的角色的自由格式描述。
高级页面
消息
消息设置 确定端口如何搜索消息并在处理后管理它们。 可以将消息保存到你的 已发送 文件夹,或者可以根据 已发送 文件夹方案将它们保存,如下所述。
- 保存至 Sent 文件夹 选中此选项可将端口处理的文件复制到端口的已发送文件夹中。
- 已发送文件夹方案 端口根据选定的时间间隔对已发送文件夹中的文件进行分组。例如,选项每周(Weekly)指示端口每周创建一个新的子文件夹,并将本周发送的所有文件存储在该文件夹中。空白设置告诉端口将所有文件直接保存在“Sent”文件夹中。对于处理许多事务的端口,使用子文件夹可以帮助保持文件有序并提高性能。
日志
- 日志级别 端口生成的日志详细程度。当您请求技术支持时,请将其设置为 Debug。
- 日志子文件夹方案:指示端口根据所选的时间间隔对日志(Logs)文件夹中的文件进行分组。每周(Weekly)选项(默认设置)指示端口每周创建一个新子文件夹,并将该周的所有日志存储在其中。如果此设置留空,则端口将所有日志直接保存在日志文件夹中。对于处理大量事务的端口,使用子文件夹有助于保持日志井然有序并提高性能。
- 记录消息内容 勾选此项后,已处理文件的日志条目将包含该文件本身的副本。如果禁用此项,您可能无法从输入或输出页面下载该文件的副本。
其他设置
- 延迟处理 放置在输入文件夹中的文件的处理延迟的时间量(以秒为单位)。 这是一个遗留设置。 最佳实践是使用 File 端口 来管理本地文件系统,而不是此设置。
特殊设置
特殊设置 适用于特定用例。
- 其他设置 允许在以分号分隔的列表中配置隐藏的端口设置,例如
setting1=value1;setting2=value2。 正常的端口用例和功能不需要使用这些设置。
自动化
自动化设置
与端口自动处理文件相关的设置。
- 发送 到达端口的消息是否自动处理。
性能
与端口资源分配相关的设置。
- 最大工作线程数 此端口上处理文件时从线程池中消耗的最大工作线程数。如果设置,则会覆盖 高级设置 页面的 性能设置 部分的默认设置。
- 最大文件数 分配给端口的每个线程发送的最大文件数。如果设置,则会覆盖 高级设置 页面的 性能设置 部分的默认设置。
通知选项卡
与配置通知相关的设置。
在执行服务级别协议 (SLA) 之前,需要设置电子邮件通知以接收通知。默认情况下,知行之桥使用 通知 选项卡上的全局设置。要为此端口使用其他设置,请启用覆盖全局设置。
默认情况下,错误通知处于启用状态,这意味着每当出现错误时都会发送电子邮件。要关闭错误通知,请取消选中启用复选框。
输入主题(必填),然后(可选)输入以逗号分隔的收件人电子邮件列表。
SLA 选项卡
与配置服务级别协议 (SLA) 相关的设置。
SLA 允许配置预期流程中端口发送或接收的数据量,并设置预期达到该数据量的时间范围。当 SLA 未达到时,知行之桥会发送电子邮件警告用户,并将 SLA 标记为_存在风险_,这意味着如果 SLA 未能尽快达到,则会被标记为_已违反_。这让用户有机会介入并确定 SLA 未达到的原因,并采取适当的措施。如果在风险时间段结束时仍未达到 SLA,则会将 SLA 标记为_已违反_,并再次通知用户。
要定义 SLA,请启用预期数据量,然后点击设置选项卡。
![]()
- 如果端口具有单独的发送和接收操作,请使用单选按钮指定 SLA 适用的方向。
- 在窗口的预计至少部分中:
- 设置预计处理的最小事务数量(交易量)
- 使用每个字段指定时间范围
- 指示 SLA 生效的时间。如果选择开始于,请填写日期和时间字段。
- 勾选希望 SLA 生效的星期几对应的复选框。如有必要,请使用下拉菜单选择每天。
- 在窗口的将状态设置为“有风险”部分中,指定应将 SLA 标记为有风险的时间。
- 默认情况下,只有在违反 SLA 的情况下才会发送通知。要更改此设置,请勾选发送“有风险”通知。
以下示例显示了为端口配置的 SLA,该端口预计在周一至周五每天接收 1000 个文件。如果尚未收到 1000 个文件,则会在时间段结束前 1 小时发送风险通知。
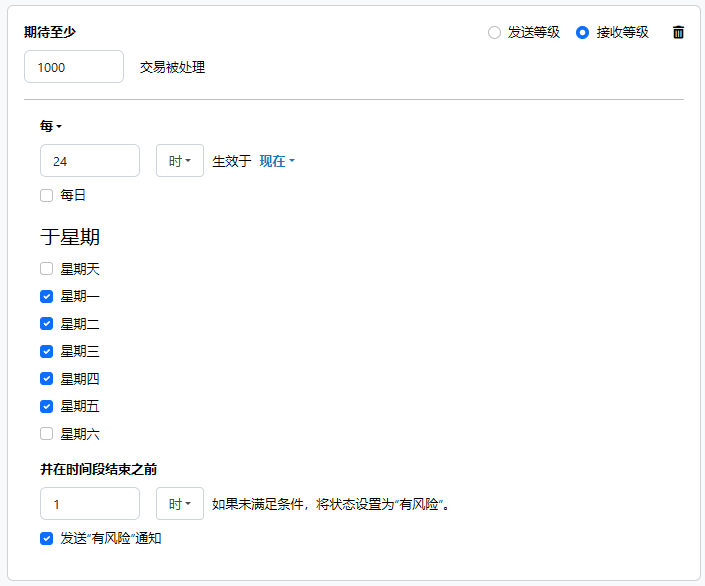
注意:如果有必要,可以关闭 SLA 通知。这在维护窗口期间非常有用。点击导航栏上的设置,然后跳转到通知 > 通用通知。点击平板和铅笔图标进行编辑,并取消勾选 SLA 通知设置。
使用示例文件
切换 示例文件 以上传一个示例输入 XML,该 XML 模拟将传递到端口中的 XML 输入。
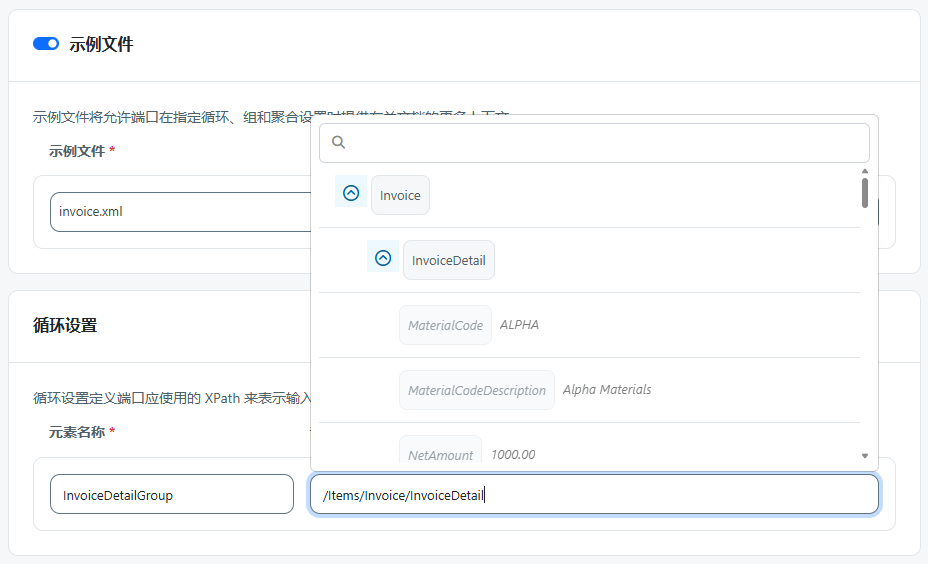
启用后,它会为 UI 中的每个 XPath 字段提供 XPath 助手,因此更容易查看文档结构并选择正确的 XPath。只能根据 XPath 为端口所代表的内容单击符合条件的 XML 元素。
例如,在 循环设置 中,只能选择父元素,因为知行之桥期望这些元素代表 记录。
然后,在分组设置中,可见元素是循环设置父元素的子元素,因为知行之桥期望 key 元素是父记录的子元素。
使用分组设置
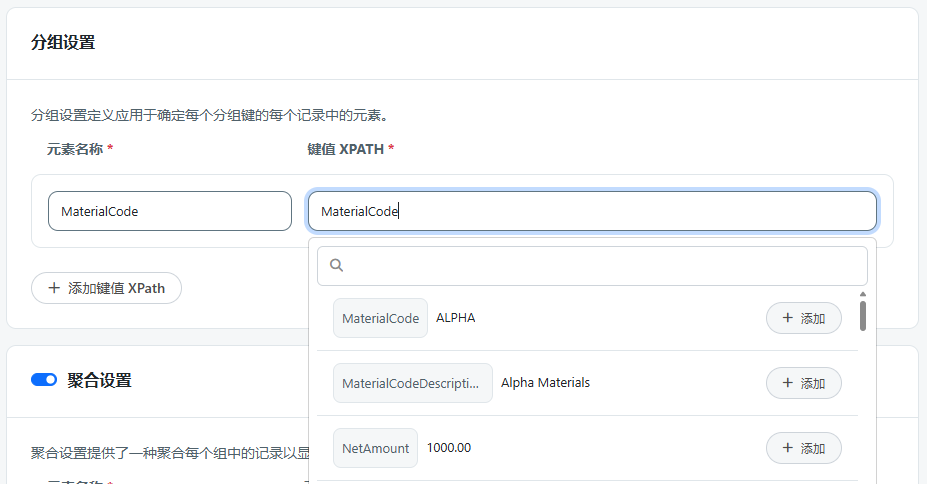
分组设置定义每个记录中用于确定每个组的键的元素。键通常是 Id 值,例如 CustomerID 或 InvoiceID。您可以有多个键,它们作为 循环设置 中设置的元素名称和 xpath 的子项出现。
- 元素名称 告诉端口在输出文件中分组时要使用的 XML 元素的名称。这通常与 键值 XPath 指向的输入文件中的元素名称相同,但您可以使用不同的名称。
- 键值 XPath 是用作 key(要分组的依据)的元素的输入文件中的 XPath。键值 XPath 相对于 记录 XPath。
例如,在下面的 XML 中,<MaterialCode> 元素是键。这样,就可以在输出中将ALPHA、BRAVO和CHARLIE的所有出现组合在一起,而不是每个出现多个。
<Items>
<Invoice>
<InvoiceDetail>
<MaterialCode>ALPHA</MaterialCode>
<MaterialCodeDescription>Alpha Materials</MaterialCodeDescription>
<NetAmount>1000.00</NetAmount>
</InvoiceDetail>
<InvoiceDetail>
<MaterialCode>ALPHA</MaterialCode>
<MaterialCodeDescription>Alpha Materials</MaterialCodeDescription>
<NetAmount>2000.00</NetAmount>
</InvoiceDetail>
<InvoiceDetail>
<MaterialCode>BRAVO</MaterialCode>
<MaterialCodeDescription>Bravo Materials</MaterialCodeDescription>
<NetAmount>100.00</NetAmount>
</InvoiceDetail>
<InvoiceDetail>
<MaterialCode>CHARLIE</MaterialCode>
<MaterialCodeDescription>Charlie Materials</MaterialCodeDescription>
<NetAmount>500.00</NetAmount>
</InvoiceDetail>
<InvoiceDetail>
<MaterialCode>CHARLIE</MaterialCode>
<MaterialCodeDescription>Charlie Materials</MaterialCodeDescription>
<NetAmount>100.00</NetAmount>
</InvoiceDetail>
</Invoice>
</Items>
使用聚合设置
聚合设置控制端口应如何聚合数据。可以定义一个 XPath,其中包含要对其执行操作运算符的值(MIN、MAX、SUM、AVG、COUNT、CONCATENATE),然后端口对组中的所有记录执行该运算符。一个常见示例是对每条记录的价格进行求和。
以下示例使用上图中描述的循环设置和分组设置,以及以下聚合设置:
使用上一节中的 XML 会生成一个输出 XML,其中每个关键元素(MaterialCode)都有一个InvoiceDetailGroup。每个InvoiceDetailGroup内都有来自分组设置的MaterialCode键,以及来自聚合设置的计算出的NetAmountSUM。最后,包括原始的InvoiceDetail元素及其子元素:
<Items>
<Invoice>
<InvoiceDetailGroup>
<MaterialCode>ALPHA</MaterialCode>
<NetAmountSUM>3000</NetAmountSUM>
<InvoiceDetail>
<MaterialCode>ALPHA</MaterialCode>
<MaterialCodeDescription>Alpha Materials</MaterialCodeDescription>
<NetAmount>1000.00</NetAmount>
</InvoiceDetail>
<InvoiceDetail>
<MaterialCode>ALPHA</MaterialCode>
<MaterialCodeDescription>Alpha Materials</MaterialCodeDescription>
<NetAmount>2000.00</NetAmount>
</InvoiceDetail>
</InvoiceDetailGroup>
<InvoiceDetailGroup>
<MaterialCode>BRAVO</MaterialCode>
<NetAmountSUM>100.00</NetAmountSUM>
<InvoiceDetail>
<MaterialCode>BRAVO</MaterialCode>
<MaterialCodeDescription>Bravo Materials</MaterialCodeDescription>
<NetAmount>100.00</NetAmount>
</InvoiceDetail>
</InvoiceDetailGroup>
<InvoiceDetailGroup>
<MaterialCode>CHARLIE</MaterialCode>
<NetAmountSUM>600</NetAmountSUM>
<InvoiceDetail>
<MaterialCode>CHARLIE</MaterialCode>
<MaterialCodeDescription>Charlie Materials</MaterialCodeDescription>
<NetAmount>500.00</NetAmount>
</InvoiceDetail>
<InvoiceDetail>
<MaterialCode>CHARLIE</MaterialCode>
<MaterialCodeDescription>Charlie Materials</MaterialCodeDescription>
<NetAmount>100.00</NetAmount>
</InvoiceDetail>
</InvoiceDetailGroup>
</Invoice>
</Items>
由于已经将关联记录作为键的嵌套子项,而不是扁平结构,因此当它进入 XML Map 端口时,此 XML 更容易处理。
宏
在文件命名策略中使用宏可以提高组织效率和对数据的上下文理解。 通过将宏合并到文件名中,可以动态地包含相关信息,例如标识符、时间戳和消息头信息,从而为每个文件提供有价值的上下文。 这有助于确保文件名反映对组织重要的详细信息。
知行之桥 支持这些宏,它们都使用以下语法:%Macro%。
| 宏 | 描述 |
|---|---|
| ConnectorID | 替换为端口的 ConnectorID。 |
| Ext | 替换为端口当前正在处理的文件的文件扩展名。 |
| Filename | 替换为端口当前正在处理的文件的文件名(包括扩展名)。 |
| FilenameNoExt | 替换为端口当前正在处理的文件的文件名(不带扩展名)。 |
| MessageId | 计算端口输出的消息的 MessageId。 |
| RegexFilename:pattern | 将正则表达式模式应用于端口当前正在处理的文件的文件名。 |
| Header:headername | 替换为端口正在处理的当前消息的目标消息头 (headername) 的值。 |
| LongDate | 以常规格式计算系统的当前日期时间(例如,2024 年 1 月 24 日星期三)。 |
| ShortDate | 以 yyyy-MM-dd 格式计算系统的当前日期时间(例如 2024-01-24)。 |
| DateFormat:format | 以指定格式(format)计算系统的当前日期时间。 有关可用的日期时间格式,请参阅示例日期格式 |
| Vault:vaultitem | 计算指定保管库项目的值。 |
示例
某些宏(例如 %Ext% 和 %ShortDate%)不需要参数,但其他宏则需要。 所有带有参数的宏都使用以下语法:%Macro:argument%
以下是带有参数的宏的一些示例:
- %Header:headername%:其中
headername是消息上消息头的名称。 - %Header:mycustomheader% 解析为输入消息上设置的
mycustomheader消息头的值。 - %Header:ponum% 解析为输入消息上设置的
ponum消息头的值。 - %RegexFilename:pattern%:其中“pattern”是正则表达式模式。 例如,
%RegexFilename:^([\w][A-Za-z]+)%匹配并解析为文件名中的第一个单词,并且不区分大小写(test_file.xml解析为test) 。 - %Vault:vaultitem%:其中
vaultitem是 vault 中项目的名称。 例如,%Vault:companyname%解析为存储在保管库中的companyname项的值。 - %DateFormat:format%:其中
format是可接受的日期格式(有关详细信息,请参阅示例日期格式)。 例如,%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%解析为文件上的日期和时间戳。
还可以创建更复杂的宏,如以下示例所示:
- 将多个宏组合在一个文件名中:
%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%%EXT% - 包括宏之外的文本:
MyFile_%DateFormat:yyyy-MM-dd-HH-mm-ss-fff% - 在宏中包含文本:
%DateFormat:'DateProcessed-'yyyy-MM-dd_'TimeProcessed-'HH-mm-ss%