Split 端口
Version 26.2.9636
Version 26.2.9636
Split 端口
Split 端口可以将单个 XML 文件拆分为多个 XML 文件。
核心功能
- 基于 XPath 的 XML 文件拆分,支持将批量记录分离为单个文件
- 可配置的批量分组,支持通配符 XPath 以实现动态元素匹配
- 文件的最大记录数控制,用于管理输出文件的大小
概述
Split 端口配置有一个 Xpath,应根据 Xpath 将输入的 XML 文件拆分为多个 XML 文件。当 XML 中含有“多批”的数据,例如多个订单,多个订单行或多个客户记录时,此功能会很有用。Split 端口根据订单/项目/记录将这“批”的 XML 数据拆分为单独的 XML 文件。
端口配置
本部分包括所有可配置的端口属性。
设置
配置
与端口操作有关的设置。
- 端口 Id 端口的静态、唯一标识符。
- 端口类型 显示端口类型及其用途的描述。
- 端口描述 一个可选字段,用于提供端口及其在流中的角色的自由格式描述。
- Xpath 在 XML 结构中的元素路径,根据此路径进行拆分。指定的 Xpath 每次一出现就会产生一个单独输出的 XML 文件。
高级设置
之前没有包含的设置。
- 批量大小 控制将多少消息放入批处理组中。 默认为1,表示不创建批次组。 如果将其设置为小于 1 的值,则所有消息都包含在单个批处理组中。 如果将其设置为大于 1 的值,则每个批次组包含此处指示的消息数。 有关详细信息,请参阅示例。
- 最大记录数 单个输出消息中可包含的最大记录数。使用 -1 表示所有输出记录应放在一个文件中,使用 0 表示端口可以根据配置的 输出文件格式 进行判断。默认情况下,XML 格式每个文件输出一条记录,而平面文件格式则将所有记录放在一个文件中。
- 本地文件名格式 用于为端口输出的消息分配文件名的方案。 可以在文件名中动态使用宏来包含标识符和时间戳等信息。 有关详细信息,请参阅宏。
高级页面
消息
- 保存至 Sent 文件夹 选中此选项可将端口处理的文件复制到端口的已发送文件夹中。
- 已发送文件夹方案 指示端口根据选定的时间间隔对已发送文件夹中的消息进行分组。 例如,Weekly 选项指示端口每周创建一个新的子文件夹,并将该周的所有消息存储在该文件夹中。 空白设置告诉端口将所有消息直接保存在“已发送”文件夹中。 对于处理许多消息的端口,使用子文件夹有助于保持消息的组织性并提高性能。
日志
- 日志级别 端口生成的日志的详细程度。 当端口请求支持时,请将其设置为 Debug。
- 日志子文件夹方案:指示端口根据所选的时间间隔对日志(Logs)文件夹中的文件进行分组。每周(Weekly)选项(默认设置)指示端口每周创建一个新子文件夹,并将该周的所有日志存储在其中。如果此设置留空,则端口将所有日志直接保存在日志文件夹中。对于处理大量事务的端口,使用子文件夹有助于保持日志井然有序并提高性能。
- 保留消息副本 选中此项可使已处理文件的日志条目包含文件本身的副本。 如果禁用此功能,端口可能无法从 交易 选项卡下载文件的副本。
其他设置
- 延迟处理 放置在输入文件夹中的文件的处理延迟的时间量(以秒为单位)。 这是一个遗留设置。 最佳实践是使用 File 端口 来管理本地文件系统,而不是此设置。
特殊设置
特殊设置 适用于特定用例。
- 其他设置 允许在以分号分隔的列表中配置隐藏的端口设置,例如
setting1=value1;setting2=value2。 正常的端口用例和功能不需要使用这些设置。
通知选项卡
与配置通知相关的设置。
在执行服务级别协议 (SLA) 之前,需要设置电子邮件通知以接收通知。默认情况下,知行之桥使用 通知 选项卡上的全局设置。要为此端口使用其他设置,请启用覆盖全局设置。
默认情况下,错误通知处于启用状态,这意味着每当出现错误时都会发送电子邮件。要关闭错误通知,请取消选中启用复选框。
输入主题(必填),然后(可选)输入以逗号分隔的收件人电子邮件列表。
SLA 选项卡
与配置服务级别协议 (SLA) 相关的设置。
SLA 允许配置预期流程中端口发送或接收的数据量,并设置预期达到该数据量的时间范围。当 SLA 未达到时,知行之桥会发送电子邮件警告用户,并将 SLA 标记为_存在风险_,这意味着如果 SLA 未能尽快达到,则会被标记为_已违反_。这让用户有机会介入并确定 SLA 未达到的原因,并采取适当的措施。如果在风险时间段结束时仍未达到 SLA,则会将 SLA 标记为_已违反_,并再次通知用户。
要定义 SLA,请启用预期数据量,然后点击设置选项卡。
![]()
- 如果端口具有单独的发送和接收操作,请使用单选按钮指定 SLA 适用的方向。
- 在窗口的预计至少部分中:
- 设置预计处理的最小事务数量(交易量)
- 使用每个字段指定时间范围
- 指示 SLA 生效的时间。如果选择开始于,请填写日期和时间字段。
- 勾选希望 SLA 生效的星期几对应的复选框。如有必要,请使用下拉菜单选择每天。
- 在窗口的将状态设置为“有风险”部分中,指定应将 SLA 标记为有风险的时间。
- 默认情况下,只有在违反 SLA 的情况下才会发送通知。要更改此设置,请勾选发送“有风险”通知。
以下示例显示了为端口配置的 SLA,该端口预计在周一至周五每天接收 1000 个文件。如果尚未收到 1000 个文件,则会在时间段结束前 1 小时发送风险通知。
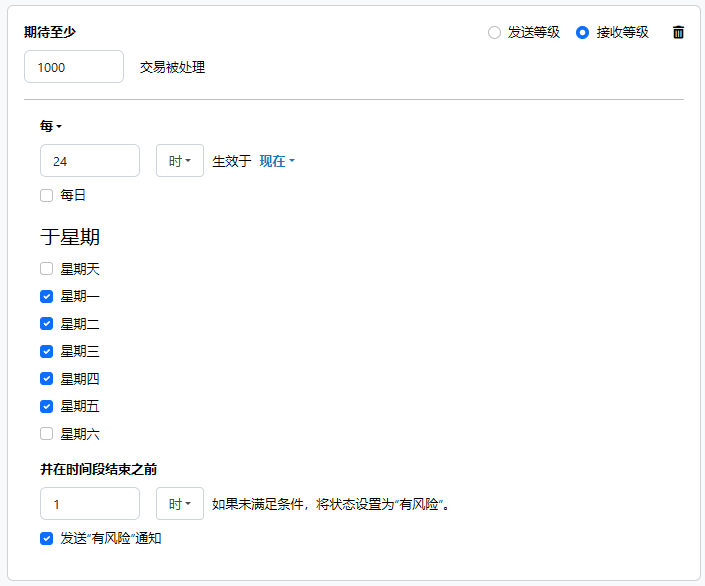
注意:如果有必要,可以关闭 SLA 通知。这在维护窗口期间非常有用。点击导航栏上的设置,然后跳转到通知 > 通用通知。点击平板和铅笔图标进行编辑,并取消勾选 SLA 通知设置。
自动化页面
自动化
与端口自动处理文件相关的设置。
- 发送 到达端口的消息是否自动进行处理。
性能
与端口资源分配相关的设置。
- 最大工作线程数 此端口上处理文件时从线程池中消耗的最大工作线程数。如果设置,则会覆盖 高级设置 页面的 性能设置 部分的默认设置。
- 最大文件数 分配给端口的每个线程发送的最大文件数。如果设置,则会覆盖 高级设置 页面的 性能设置 部分的默认设置。
示例
下面是一个包含多个 TransactionSet 元素的 XML 输入文件:
<Items>
<Interchange>
<Id>1</Id>
<TransactionSet>
<Data>value1</Data>
</TransactionSet>
<TransactionSet>
<Data>value2</Data>
</TransactionSet>
<TransactionSet>
<Data>value3</Data>
</TransactionSet>
<TransactionSet>
<Data>value4</Data>
</TransactionSet>
</Interchange>
<Items>
Split 端口可以将输入文件拆分为两部分独立的文件输出,每个 TransactionSet 对应一个文件。要实现该功能,XPath 字段应该设置为 TransactionSet 元素的路径:
/Items/Interchange/TransactionSet
将产生以下两个输出文件:
输出 1:
<Items>
<Interchange>
<Id>1</Id>
<TransactionSet>
<Data>value1</Data>
</TransactionSet>
</Interchange>
</Items>
如果将 批量大小 设置为 2,端口将输出两个批次组,每个批次组有两条消息。 下面显示了一个批次组示例。
批处理 1
批处理消息 1:
<Items>
<Interchange>
<Id>1</Id>
<TransactionSet>
<Data>value1</Data>
</TransactionSet>
</Interchange>
</Items>
批处理消息 2:
<Items>
<Interchange>
<Id>1</Id>
<TransactionSet>
<Data>value2</Data>
</TransactionSet>
</Interchange>
</Items>
Xpath 通配符
XPath 可包包含一个通配符字符(*),以拆分给定路径下的所有元素。例如:输入的 XML 可能包含多组需要拆分为独立文件的数据。然而这些组的数据有不同的元素名称:
<Items>
<Group1>
<Data>value1</Data>
</Group1>
<Group2>
<Data>value2</Data>
</Group2>
<Group3>
<Data>value3</Data>
</Group3>
</Items>
这些组可以通过将 Xpath 设置成以下值来拆分:
/Items/*
将会产生以下三个输出文件:
输出 1:
<Items>
<Group1>
<Data>value1</Data>
</Group1>
</Items>
输出 2:
<Items>
<Group2>
<Data>value2</Data>
</Group2>
</Items>
输出 3:
<Items>
<Group3>
<Data>value3</Data>
</Group3>
</Items>
宏
在文件命名策略中使用宏可以提高组织效率和对数据的上下文理解。 通过将宏合并到文件名中,可以动态地包含相关信息,例如标识符、时间戳和消息头信息,从而为每个文件提供有价值的上下文。 这有助于确保文件名反映对组织重要的详细信息。
知行之桥 支持这些宏,它们都使用以下语法:%Macro%。
| 宏 | 描述 |
|---|---|
| ConnectorID | 替换为端口的 ConnectorID。 |
| Ext | 替换为端口当前正在处理的文件的文件扩展名。 |
| Filename | 替换为端口当前正在处理的文件的文件名(包括扩展名)。 |
| FilenameNoExt | 替换为端口当前正在处理的文件的文件名(不带扩展名)。 |
| MessageId | 计算端口输出的消息的 MessageId。 |
| RegexFilename:pattern | 将正则表达式模式应用于端口当前正在处理的文件的文件名。 |
| Header:headername | 替换为端口正在处理的当前消息的目标消息头 (headername) 的值。 |
| LongDate | 以常规格式计算系统的当前日期时间(例如,2024 年 1 月 24 日星期三)。 |
| ShortDate | 以 yyyy-MM-dd 格式计算系统的当前日期时间(例如 2024-01-24)。 |
| DateFormat:format | 以指定格式(format)计算系统的当前日期时间。 有关可用的日期时间格式,请参阅示例日期格式 |
| Vault:vaultitem | 计算指定保管库项目的值。 |
| Counter | 用作拆分 XML 后每个输出文件的唯一标识符。第一个输出文件使用“1”作为此值,后续每个输出文件都会递增此值。 |
示例
某些宏(例如 %Ext% 和 %ShortDate%)不需要参数,但其他宏则需要。 所有带有参数的宏都使用以下语法:%Macro:argument%
以下是带有参数的宏的一些示例:
- %Header:headername%:其中
headername是消息上消息头的名称。 - %Header:mycustomheader% 解析为输入消息上设置的
mycustomheader消息头的值。 - %Header:ponum% 解析为输入消息上设置的
ponum消息头的值。 - %RegexFilename:pattern%:其中“pattern”是正则表达式模式。 例如,
%RegexFilename:^([\w][A-Za-z]+)%匹配并解析为文件名中的第一个单词,并且不区分大小写(test_file.xml解析为test) 。 - %Vault:vaultitem%:其中
vaultitem是 vault 中项目的名称。 例如,%Vault:companyname%解析为存储在保管库中的companyname项的值。 - %DateFormat:format%:其中
format是可接受的日期格式(有关详细信息,请参阅示例日期格式)。 例如,%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%解析为文件上的日期和时间戳。
还可以创建更复杂的宏,如以下示例所示:
- 将多个宏组合在一个文件名中:
%DateFormat:yyyy-MM-dd-HH-mm-ss-fff%%EXT% - 包括宏之外的文本:
MyFile_%DateFormat:yyyy-MM-dd-HH-mm-ss-fff% - 在宏中包含文本:
%DateFormat:'DateProcessed-'yyyy-MM-dd_'TimeProcessed-'HH-mm-ss%